无
”python sklearn“ 的搜索结果
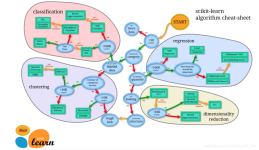
1.主要功能如下: 1.classification分类 2.Regression回归 3.Clustering聚类 4.Dimensionality reduction降维 5.Model selection模型选择 6.Preprocessing预处理 2.主要模块分类: ...1.sklearn.base: Base classes ...

Python的机器学习库scikit-learn(简称sklearn)是一个非常流行的工具,用于实现各种机器学习算法和数据预处理技术。下面是安装scikit-learn的步骤: 1. 确保你已经安装了Python。... 2. 打开命令行终端(Windows用户...
十折交叉验证是一种常用的交叉验证方法,在python的sklearn库中可以通过KFold方法实现。具体步骤如下: 1. 从sklearn.model_selection库中导入KFold。 2. 定义KFold对象并设置参数,包括划分折数和是否打乱顺序等。...
本程序是在python中完成,基于sklearn.cluster中的k-means聚类包来实现数据的聚类,对于里面使用的数据格式如下:(注意更改程序中的相关参数) 138 0 124 1 127 2 129 3 119 4 127 5 124 6 120 7 ...
好的,您的问题是关于使用sklearn的乳腺癌数据集,这是一个非常常见的机器学习数据集。您可以使用以下代码来加载乳腺癌数据集: ```python from sklearn.datasets import load_breast_cancer ...
I'm working on a project using Python(3.6) and Sklearn.I have done classifications but when I try to apply it for reshaping in order to use it with fit method of sklearn it returns an error.Here's wha...
八爪鱼采集器能取代python爬虫吗只喜欢热闹,耐不住寂寞的人,爱情也许也难以长久,因为他不知怎么忍受清静的二人世界。把你的名字写在小编手心里,摊开时是想念,握紧时是幸福,小编只想这样,手牵手给你一世的温柔...
原标题:sklearn入门之多元线性回归本文作者:杨长青本文编辑:胡 婧技术总编:张学人 scikit-learn又称sklearn是基于python的一个强大的机器学习库,它建立在numpy,scipy和matplotlib模块之上能够为用户提供各种...
我有一个时间序列是这样的:date var1 var2 var3 var4 var5 var60 2004-09-30 6.252216 10.502101 4.965370 26.828754 3.321060 2.7236861 2004-10-29 6.861840 9.776618 4.719399 ...
一、自带的小数据集(packageddataset):sklearn.datasets.load_1)鸢尾花数据集:load_iris():用于分类任务的数据集2)手写数字数据集:load_digits():用于分类任务或者降维任务的数据集3)乳腺癌数据集load-barest-...
本文实例讲述了Python使用sklearn实现的各种回归算法。分享给大家供大家参考,具体如下:使用sklearn做各种回归基本回归:线性、决策树、SVM、KNN集成方法:随机森林、Adaboost、GradientBoosting、Bagging、Extra...
今天在安装python 的 sklearn 包时出现了Cannot uninstall 'numpy' 和Cannot uninstall 'scipy'错误,下面记录了我尝试了很多网上的方法后最终成功的解决方法。终端执行pip install scikit-learn后,出现 Cannot ...
解决方法:在编程过程中,遇到很多错误,提示都是unresolved reference,在进行先关搜素后,从stackoverflow上的相关问题得到启发,具体步骤如下:1、点击菜单栏上的File -> Setting ->Build,Executing,...
一、Sklearn介绍scikit-learn是Python语言开发的机器学习库,一般简称为sklearn,目前算是通用机器学习算法库中实现得比较完善的库了。其完善之处不仅在于实现的算法多,还包括大量详尽的文档和示例。...
这是一个手写数字的识别实验,是一个sklearn在现实中使用的案例。原例网址里有相应的说明和代码。首先实验的数据量为1797,保存在sklearn的dataset里。我们可以直接从中获取。每一个数据是有image,target两部分组成...
一、Sklearn介绍scikit-learn是Python语言开发的机器学习库,一般简称为sklearn,目前算是通用机器学习算法库中实现得比较完善的库了。其完善之处不仅在于实现的算法多,还包括大量详尽的文档和示例。...
向量器将语料库(例如文本文档)转换为向量Vector Space Model。有很多方法可以做到这一点,而结果将取决于所使用的技术。矢量器是必要的,因为模型处理的是数字,而不是文字。具体来说,CountVectorizer的实现将生成...
sklearn特征选择包中的chi2函数返回卡方统计和p值。它应该是对称的,在这个意义上,卡方统计量是相同的,不管变量是以什么顺序给出的,但它似乎不是。在下面是一个代码示例:import numpy as npimport pandas as pd...
cross_val_score是一个helper函数,它包装scikit learn的各种对象以进行交叉验证(例如KFold,StratifiedKFold)。它根据使用的scoring参数返回一个分数列表(对于分类问题,我相信默认情况下是accuracy)。...
我使用GridSearchCV来调整SVM分类器,然后绘制一条学习曲线。然而,除非我在绘制学习曲线之前设置一个新的分类器,否则我会遇到一个索引器,而且我不太清楚原因。在我的简历/分类器设置如下:# Set up classifierclf...

【代码】分类指标计算 Precision、Recall、F-score、TPR、FPR、TNR、FNR、AUC、Accuracy。
简单起见,考虑到现在考研比较内卷,那么假设用三个指标评价是否录取,即本科是否为985;考研分数A(前10%),B(10%-30%),C(30%-60%),D(后40%)四档;本科发文章A(Nature级别), B(SCI),C(其他期刊),D(无期刊),现有...

(你不要直接搜sklearn,你下载这个包,你import导入的时候,还是会报错)大概长这样,然后你下载,这样子就ok了。然后你就可以正常导入sklearn的库了。下一步我们搜索 scikit-learn 然后下载。...
数据分布比较均匀效果可以,数据分布不均匀,两头比较少,效果不好。 labels = read_labels(u"labels.txt") predicts = read_Feautures(u"scores.txt") levels=(1e-6, 1e-5, 1e-4, 1e-3, 1e-2) ...
推荐文章
- c语言链表查找成绩不及格,【查找链表面试题】面试问题:C语言学生成绩… - 看准网...-程序员宅基地
- 计算机网络:20 网络应用需求_应用对网络需求-程序员宅基地
- BEVFusion论文解读-程序员宅基地
- multisim怎么设置晶体管rbe_山东大学 模电实验 实验一:单极放大器 - 图文 --程序员宅基地
- 华为OD机试真题-灰度图恢复-2023年OD统一考试(C卷)-程序员宅基地
- 【机器学习】(周志华--西瓜书) 真正例率(TPR)、假正例率(FPR)与查准率(P)、查全率(R)_真正例率和假正例率,查准率,查全率,概念,区别,联系-程序员宅基地
- Python Django 版本对应表以及Mysql对应版本_django版本和mysql对应关系-程序员宅基地
- Maven的pom.xml文件结构之基本配置packaging和多模块聚合结构_pom <packaging>-程序员宅基地
- Composer 原理(二) -- 小丑_composer repositories-程序员宅基地
- W5500+F4官网TCPClient代码出现IP读取有问题,乱码问题_w5500 ping 网络助手 乱码 send(sock_tcps,tcp_server_buff,-程序员宅基地